
3 Computer vision and machine learning
As highlighted in Figure 2.1, there are two main ML components to HTR/OCR transcription workflows, a segmentation component and a text transcription component. To understand the software (frameworks) for HTR/OCR solutions a brief introduction in ML and computer vision methods is required. This allows you to understand potential pitfalls better.
3.1 Computer vision
Although computer vision methods, broadly, include ML methods the classical approaches differ significantly from ML methods. Classic computer vision methods, as discussed below LINK, are applied on pixel (region) or image based transformation. These methods are often used in the pre-processing of images before a machine learning algorithm is applied (FIGURE LINK). Classical examples are the removal of uneven lighting across an image using adaptive histogram equalization, the detection of structuring elements such as linear features using a Hough transform, or the adaptive thresholding of an image from colour to black-and-white only. These algorithms also serve an important role in the creation of additional data from a single reference dataset, through data augmentation LINK.
3.2 Machine Learning
The machine learning components of the text segmentation and transcriptions rely on common machine learning algorithms and logic. To better understand these tasks, and how training methods influences the success of these models, I will summarize some of these common building blocks. These are vulgarized and simplified descriptions to increase the broad understanding of these processes, for in depth discussions I refer to the linked articles in the text and machine learning textbooks at the end of this course.

Machine learning models are non-deterministic and rely on learning or training (an optimization method) on ground truth (reference) data. The most simple machine learning algorithm is a simple linear regression. In a simple linear regression one optimizes (trains) a slope and intercept parameter to fit the observed response (ground truth) to explanatory variables (data). The more complex the task, the more parameters and data are required. Although oversimplified, the very tongue in cheek cartoon by XKCD is a good mental model of what happens on an abstract level where we shuffle model parameters until we get good correspondence between the data input and the ground truth observations.
From this one can deduce a number of key take-home message:
- a sufficient amount of training data
- an appropriate ML and shuffling (optimization) algorithm
- a ML model is limited by the representations within the training data
3.2.1 Detecting patterns: convolutional neural networks (CNN)
The analysis of images within the context of machine learning often (but not exclusively) happens using a convolutional neural networks (CNNs). Conceptually a CNN can be see as taking sequential sections of the image and summarizing them (i.e. convolve them) using a function (a filter), to a lower aggregated resolution (FIGURE XYZ). This reduces the size of the image, while at the same time while summarizing a certain characteristic using a filter function. One of the most simple functions would be taking the average value across a 3x3 window.
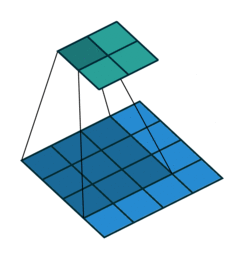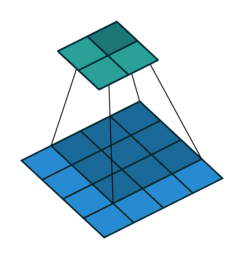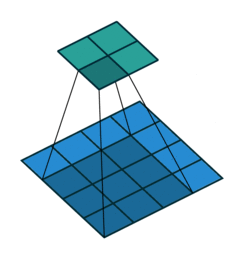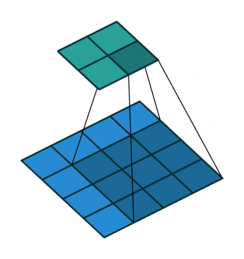
It is important to understand this concept within the context of text recognition and classification tasks in general. It highlights the fact that ML algorithms do not “understand” (handwritten) text. Where people can make sense of handwritten text by understanding the flow, in addition to recognizing patterns, ML approaches focus on patterns, shapes or forms. However, some form of memory can be included using other methods.
3.2.2 Memory and context: recurrent neural networks
A second component to many recognition tasks is a form of memory. Where the CNN encodes for patterns it does so without explicitly taking into account the relative position of these patterns and their relationship to adjacent ones. Here, Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM) networks provide a solution. These algorithms allow for some of the information of adjacent data (either in time or space) to be retained to provide context on the current (time or space) position. Both these approaches can be uni- or bi-directional. In the former, the direction of processing matters in the latter it doesn’t.
3.2.3 Negative space: connectionist temporal classification
In speech and written text much of the structure is defined not only by what is there, the spoken and written words, but also what is not there, the pauses and spacing. Taken to the extreme the expressionist / dadaist poem “Boem paukeslag” by Paul van Ostaijen is an example of irregularity in typeset text. These irregularities or negative space in the pace of writing is another hurdle for text recognition algorithms. Generally, we want a readable text as output of our ML models not dadaist impressions with large gaps.

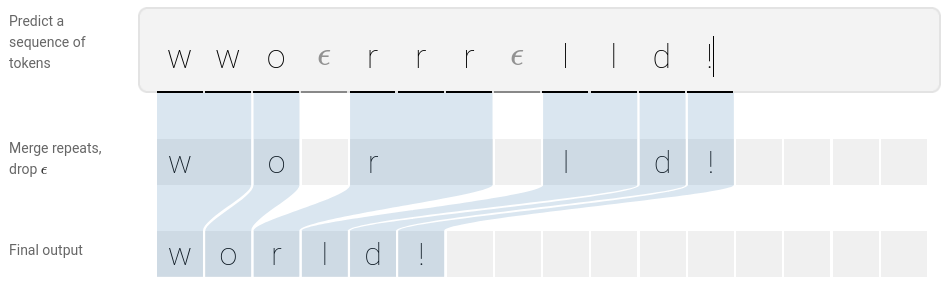
These issues in detecting uneven spacing are addressed using the Connectionist Temporal Classification (CTC). This function is applied to the RNN and LSTM output, where it collapses a sequence of recurring labels through oversampling to its most likely reduced form.
3.2.4 Data augmentation
Sufficient data is key in training a ML model which performs well. However, at times you might be limited in the data you can access for training. A common issue is that limited ground truth data (labels, text transcriptions) are available. Data augmentation is a way to slightly alter a smaller existing dataset in order to create a larger, partially, artificial dataset. Within the context of HTR/OCR one can generate slight variations of the same text image and label pair through computer vision (or machine learning) based alterations, such as rotating skewing and introducing noise to the image.

3.3 Implementation
Putting all the pieces together the most common ML implementation of text segmentation rely heavily on CNN based segmentation networks, while text recognition often if not always takes the form of a CNN + (bidirectional) LSTM/RNN + CTC network. When reading technical documentation on the architecture of models in text transcription frameworks you might come across these terms. Depending on the implementation or framework used data augmentation during training might be provided to increase the scope of the model and increase the chances of Out-Of-Distribution (OOD) generalization.
3.3.1 Out-of-distribution generalization in text transcription
Handwritten text or old print is highly varying in shape form and retained quality. This pushes trained models towards poor performance as the chances of good OOD generalization are small. In short, two text styles are rarely the same or not similar enough for a trained model to be transferred to a new, seemingly similar, transcription task.